
decoding neural speech
For those who have lost the ability to speak, even basic communication can become an immense challenge. Neural speech-to-text technology represents a potentially revolutionary shift in how we approach this problem. It moves beyond traditional speech recognition, which relies on audible sounds, and attempts to directly decode intended speech from brain activity. This isn’t about reading minds; it’s about interpreting the signals the brain already uses to formulate speech.
The idea of connecting the brain to computers – a brain-computer interface, or BCI – isn’t new. Early BCIs focused on simple control signals, like moving a cursor on a screen. But over the past decade, the field has rapidly evolved. We're now seeing systems capable of decoding increasingly complex brain activity. This progress is fueled by advancements in neuroimaging, machine learning, and signal processing.
Traditional speech recognition converts acoustic signals into text. It’s remarkably good, but it fails when there are no acoustic signals. Neural speech-to-text bypasses this limitation entirely. It focuses on the neural patterns associated with speech, regardless of whether the vocal cords are functioning. The key difference is the input: sound waves versus brain waves. This makes it a game changer for individuals with severe paralysis or speech impairments.
This technology isn’t just about restoring the ability to say words; it’s about restoring the ability to communicate with the same speed and nuance as before. That distinction is huge. It’s about regaining a fundamental part of what makes us human.
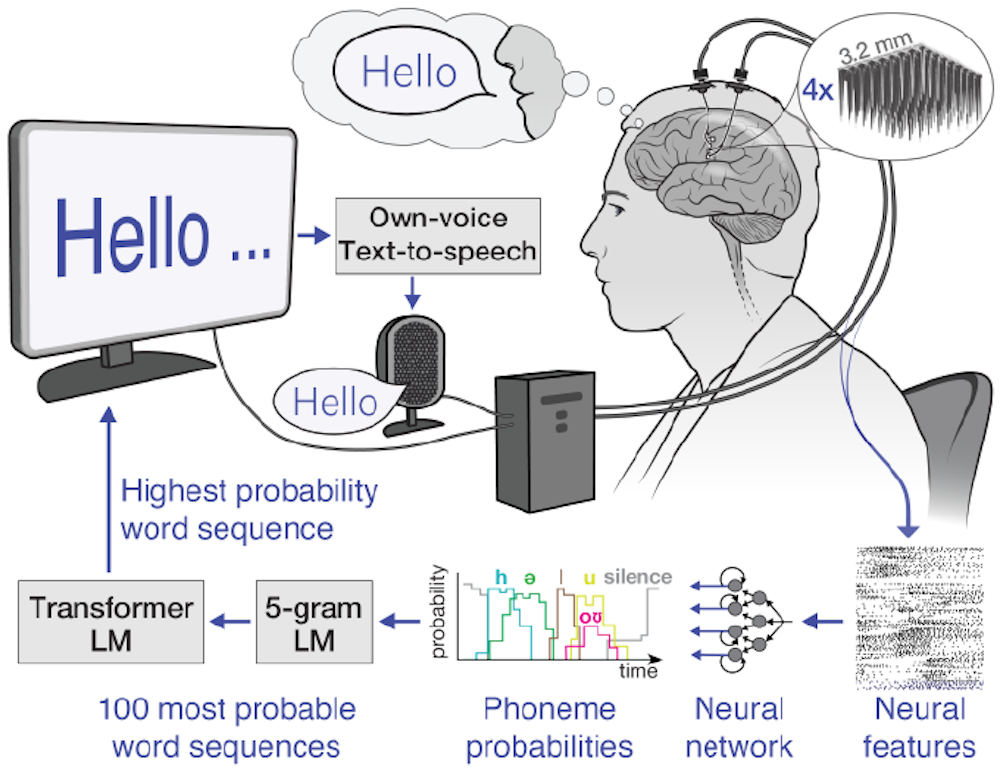
the UC Davis ALS study
In December 2023, UC Davis Health announced a remarkable achievement: a man with amyotrophic lateral sclerosis (ALS), also known as Lou Gehrig’s disease, was able to "speak’ in real-time using a brain-computer interface (health.ucdavis.edu). This wasn"t a simple, pre-programmed set of phrases. The system decoded his attempted speech, allowing him to communicate with a natural flow and vocabulary.
The process involved surgically implanting a high-density electrode array onto the surface of the man’s brain, specifically in the region controlling speech. This array, known as an electrocorticogram or ECoG grid, detects neural activity. The signals fed into a custom neural network trained to translate those specific patterns into text. The algorithm was personalized to the man's unique brain activity rather than using a generic model.
The initial results were astounding. The system achieved a word error rate of around 3%, meaning that 97% of the words decoded were accurate. While not perfect, this is a significant improvement over previous BCI systems. More importantly, the speed of communication was close to natural conversation. The man was able to express complex thoughts and ideas with relative ease. It’s a huge leap forward.
What struck me most about this case wasn't just the technological feat, but the emotional impact. The man hadn’t been able to speak clearly in years. To hear his own voice, reconstructed from his brain activity, was profoundly moving. It restored a connection to the world that had been lost. It offered a glimpse of a future where communication isn't limited by physical ability. This research is still early, and wider accessibility is some time away, but the potential is undeniable.
The team at UC Davis is continuing to refine the system, aiming to improve accuracy, speed, and robustness. They are also exploring ways to make the technology less invasive, though surgical implantation remains a necessity for the current level of performance. They're focused on making the system more adaptable to individual users and less reliant on extensive calibration.
how the technology works
At the heart of neural speech-to-text lies the ability to capture and interpret brain signals. These signals can be recorded using various methods, including electrocorticography (ECoG) – as used in the UC Davis study – and electroencephalography (EEG). ECoG involves placing electrodes directly on the surface of the brain, providing high-resolution signals. EEG uses electrodes placed on the scalp, which is non-invasive but offers lower resolution.
Regardless of the recording method, the raw brain signals are incredibly noisy and complex. They contain a lot of irrelevant information. The crucial step is to filter and process these signals to isolate those specifically related to intended speech. This is where machine learning comes in. Sophisticated neural networks are trained to recognize the patterns of brain activity associated with different phonemes – the basic units of sound – and words.
The training process is highly personalized. Each individual’s brain activity is unique, so the system needs to be calibrated to their specific patterns. This typically involves the user repeatedly attempting to speak words or phrases while the system records their brain activity. The neural network learns to map these patterns to the corresponding speech sounds. It’s not about "reading" what the person is thinking, but rather decoding the motor commands the brain is sending to the speech muscles – even if those muscles aren't actually moving.
It’s important to understand that "thinking’ the words isn"t necessarily the whole story. It's about the attempt to articulate. The brain prepares to speak even if the vocal cords aren’t functioning. The system detects these preparatory signals and translates them into text. This is a subtle but crucial distinction. The more the system learns, the more accurate and natural the communication becomes.
applications beyond ALS
While the UC Davis study focused on ALS, the potential applications of neural speech-to-text extend far beyond this condition. Stroke survivors who have lost the ability to speak due to damage to the brain’s speech centers could benefit enormously. Similarly, individuals with spinal cord injuries that affect the muscles controlling speech could regain a voice.
Cerebral palsy, a neurological disorder that affects movement and coordination, often impacts speech. Neural STT could provide an alternative communication channel for individuals with severe cerebral palsy. The technology also holds promise for those who have undergone a laryngectomy – the surgical removal of the voice box – and rely on alternative methods of communication.
Perhaps one of the most compelling applications is for individuals with locked-in syndrome, a condition where a person is aware and conscious but completely paralyzed. For these individuals, even eye-tracking can be difficult or impossible. Neural STT could offer a lifeline to the outside world, allowing them to communicate their thoughts and needs.
However, it’s crucial to be realistic. This technology isn’t a universal solution. The effectiveness of neural STT will likely vary depending on the underlying condition, the severity of the impairment, and the individual’s ability to learn and adapt to the system. Some conditions may present greater challenges than others. Further research is needed to determine which individuals are most likely to benefit.
current technical hurdles
Despite the exciting progress, significant challenges remain before neural speech-to-text becomes widely accessible. The most obvious hurdle is the invasiveness of surgical implantation required for current BCI systems. Implanting electrodes into the brain carries risks, including infection, bleeding, and tissue damage. This limits its applicability to individuals with severe impairments who are willing to undergo the procedure.
The cost of the technology is also a major barrier. The surgical procedure, the electrode array, and the specialized software all contribute to a substantial financial burden. Extensive training and calibration are also required. The system needs to be personalized to each individual’s brain activity, which can take weeks or months of dedicated effort.
Errors and misinterpretations are inevitable. Even with high accuracy rates, the system will sometimes decode words incorrectly. This can lead to frustration and communication breakdowns. Signal drift over time is a particularly concerning issue; the brain's signals can change, requiring recalibration of the system. Maintaining long-term stability is a major research focus.
Ethical considerations also loom large. Reading brain activity raises privacy concerns. Who has access to this information, and how is it protected? The potential for misuse is real. Careful consideration must be given to these ethical implications as the technology advances.
the move toward non-invasive systems
The long-term future of neural speech-to-text likely lies in non-invasive methods. Researchers are exploring high-resolution EEG systems that can capture brain activity with greater accuracy without requiring surgery. While current EEG technology lacks the precision of ECoG, advancements in sensor technology and signal processing are steadily improving its capabilities.
Another promising avenue is the development of more sophisticated machine learning algorithms. These algorithms could be designed to adapt to individual users over time, continuously learning and improving their decoding accuracy. We'll likely see systems that can handle more complex language structures and nuanced speech patterns.
Integration with other assistive technologies is also a key area of development. Imagine a neural STT system seamlessly integrated with a virtual assistant, allowing users to control their smart home devices, access information, and communicate with others using only their thoughts. Or a system that can translate thoughts directly into text on a computer screen, enabling effortless writing and communication.
I anticipate a shift towards more personalized and adaptive systems. Instead of a one-size-fits-all approach, future systems will be tailored to the unique needs and abilities of each individual. They’ll learn from the user’s behavior, adapting to their speech patterns and preferences. This will require significant advancements in machine learning and artificial intelligence.
While predicting specific timelines is difficult, the direction of research is clear. The goal is to create a seamless and intuitive communication channel that empowers individuals with speech impairments to live fuller, more independent lives. The focus is on moving beyond simply restoring speech to restoring communication in all its complexity.
Resources and Support
For individuals with speech impairments and their families, a wealth of resources and support organizations are available. The ALS Association (als.org) provides information, advocacy, and support services for people living with ALS. The American Speech-Language-Hearing Association (asha.org) offers resources and referrals for speech-language pathologists and audiologists.
Assistive technology centers, often affiliated with universities or rehabilitation hospitals, can provide evaluations, training, and access to assistive devices. These centers can help individuals identify the most appropriate technology solutions for their specific needs. Funding opportunities may be available through government programs, private foundations, and charitable organizations.
Staying informed about the latest research and clinical trials is also crucial. Websites like clinicaltrials.gov list ongoing studies related to neural speech-to-text and other assistive technologies. Connecting with online communities and support groups can provide a valuable source of information and emotional support.
- ALS Association: als.org
- American Speech-Language-Hearing Association: asha.org
- ClinicalTrials.gov: clinicaltrials.gov
Support Organizations
- ALS Association - Provides resources, advocacy, and support services for individuals and families affected by Amyotrophic Lateral Sclerosis (ALS), including information on communication devices and speech therapy.
- National Stroke Association - Offers information and support for stroke survivors and their families, including resources related to aphasia and speech difficulties post-stroke. Focuses on rehabilitation and recovery.
- American Speech-Language-Hearing Association (ASHA) - A professional, scientific, and clinical association for speech-language pathologists, audiologists, and speech scientists. Offers a ProFind tool to locate qualified professionals.
- The Stuttering Foundation - Dedicated to the prevention and treatment of stuttering and other speech and language disorders. Provides resources for individuals who stutter, their families, and professionals.
- Apraxia Kids - Focuses on childhood apraxia of speech (CAS), offering resources, support, and advocacy for children with CAS and their families. Provides information on therapy and communication strategies.
- National Aphasia Association - Supports individuals with aphasia and their families through education, advocacy, and access to resources. Offers support groups and information on communication strategies.
- Voice Disorders Support Group - A peer-to-peer support network for individuals experiencing voice disorders, including those impacting speech. Offers a forum for sharing experiences and information.




No comments yet. Be the first to share your thoughts!